Introduction to Machine Learning With H2O.ai
Harness the power of H2O for machine learning in Python with ease. Train accurate models and evaluate predictions with clear metrics, showcased through H2O's user-friendly Python interface. Perfect for efficient data science workflows.


Overview
H2O is a machine learning library for the JVM that shines because of its breadth, not only it includes excellent tools for supervised learning and predictive modeling, like Generalized Linear Models, Distributed Random Forests and Gradient Boosting Machines. But also supports Deep Learning for those looking to dive into neural networks.
But that’s just the tip of the iceberg. H2O also dives into unsupervised learning with algorithms like k-Means clustering, which is great for segmenting data into natural groupings. And if you’re into text data, their Word2Vec implementation transforms words into meaningful vectors.
Despite its foundation as a JVM library, H2O extends its accessibility far beyond the Java Virtual Machine, thanks to its versatile REST API. This architectural choice ensures that H2O can be seamlessly integrated and utilized in diverse environments, catering to a wide array of users not confined to the JVM ecosystem. The REST interface acts as a bridge, allowing for interactions with H2O's powerful machine learning capabilities from virtually any programming environment capable of making HTTP requests. This level of interoperability underscores H2O's commitment to flexibility and user convenience, ensuring that the tools are as inclusive as possible.
Moreover, the accessibility of H2O is further enhanced through dedicated libraries for Python and R, two of the most prominent languages in the data science and machine learning communities. These libraries abstract the underlying REST API calls, offering users a native and idiomatic programming experience. Whether you are a Pythonista accustomed to pandas and scikit-learn, or an R user fluent in tidyverse and caret, H2O provides you with a familiar and powerful interface to leverage its extensive machine learning algorithms. This blend of deep JVM integration with broad accessibility through REST, Python, and R, ensures that H2O stands as a versatile and indispensable tool in the modern data scientist's toolkit.
H2O's integration with Apache Spark is facilitated through Sparkling Water, a powerful extension that allows H2O's machine learning algorithms to run within the Spark ecosystem. This integration combines the best of both worlds: H2O's advanced machine learning capabilities with Spark's data processing and handling prowess. Sparkling Water is designed to work natively within Spark, enabling users to utilize H2O algorithms seamlessly alongside Spark's dataframes and RDDs. This integration supports all languages compatible with Spark, including Scala, Python (via PySpark), and R, providing a unified experience across these different programming environments.
The use of H2O within Spark through Sparkling Water does not rely on the REST API for communication between Spark and H2O components. Instead, it leverages a more direct, native approach, ensuring efficient data exchange and operation within the distributed computing environment that Spark provides. This native integration allows for tighter coupling between Spark and H2O, optimizing performance and usability. Users can initiate H2O's context within Spark's application, enabling direct operations on distributed data and leveraging Spark's infrastructure for machine learning tasks at scale. This makes Sparkling Water an ideal choice for data scientists and engineers looking to harness the combined power of Spark and H2O in their scalable data processing and machine learning projects.
A Simple Example in Python
H2O's Python module provides a convenient and powerful interface for data scientists and analysts to access H2O's machine learning capabilities within the Python ecosystem. This section will guide you through the installation process and a simple example to get you started with training and evaluating a model using H2O in Python.
Installation
To install the H2O Python module, you'll need Python and pip installed on your system. With those in place, installing H2O is as simple as running the following command in your terminal:
$ pip install setuptools
$ pip install h2o
This command downloads and installs the latest version of the H2O Python module along with its dependencies. Once the installation is complete, you're ready to start using H2O in your Python projects.
A Simple Example: Training and Evaluating a Model
In this example, we'll demonstrate how to initialize an H2O cluster, load a dataset, train a Generalized Linear Model (GLM), and evaluate its performance. We'll use the well-known Iris dataset for this purpose.
import h2o
from h2o.estimators.glm import H2OGeneralizedLinearEstimator
# Initialize the H2O cluster
h2o.init()
# Load the Iris dataset
iris = h2o.import_file("https://h2o-public-test-data.s3.amazonaws.com/smalldata/iris/iris_wheader.csv")
# Split the dataset into a train and test set
train, test = iris.split_frame(ratios=[0.8], seed=1)
# Specify the predictors and the response variable
predictors = iris.columns[:-1] # all columns except the last one
response = 'class' # the last column is the response variable
# Initialize and train the GLM model
glm_model = H2OGeneralizedLinearEstimator(family="multinomial")
glm_model.train(x=predictors, y=response, training_frame=train)
# Evaluate the model's performance on the test set
performance = glm_model.model_performance(test_data=test)
print(performance)
This simple Python script demonstrates the ease with which you can leverage H2O's machine learning algorithms. Here's a quick breakdown of what we did:
- Initialize the H2O cluster: This is your entry point to H2O's functionalities. It starts a local H2O cluster on your machine.
- Load data: We imported the Iris dataset directly from a URL. H2O supports various file formats and sources for data import.
- Prepare data: We split the dataset into training and testing sets to prepare for model training and evaluation.
- Train a model: We chose a Generalized Linear Model (GLM) for this example, specifying it to solve a multinomial classification problem.
- Evaluate the model: We assessed the model's performance on the test set, getting metrics like accuracy, confusion matrix, etc.
Using H2O with Python allows you to tap into powerful machine learning algorithms with minimal code, making it an excellent choice for both beginners and experienced data scientists.
Running the Code
Running the code is really simple:
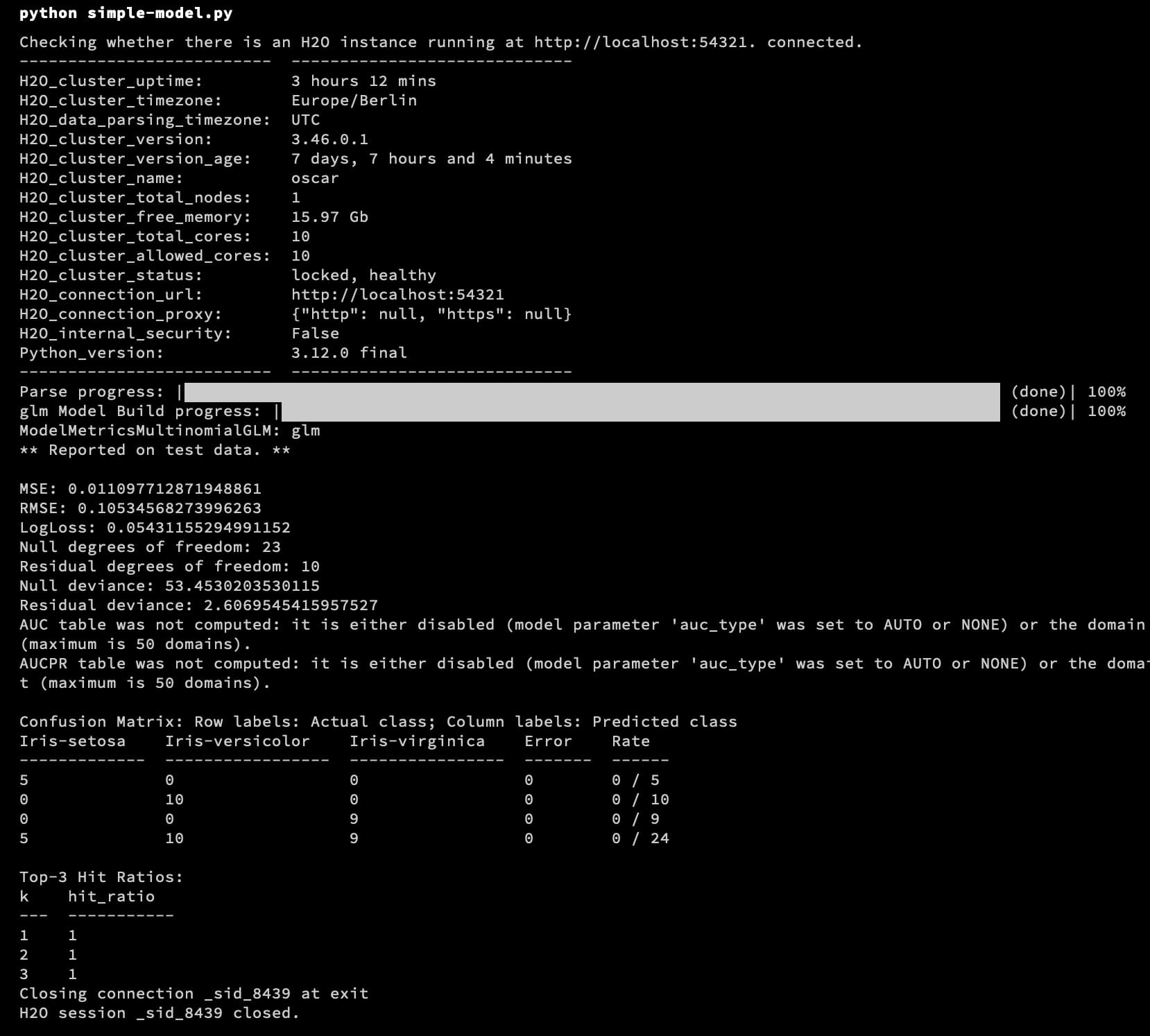
$ python simple-model.py
This starts a cluster, trains the model and evaluates its performance:
Conclusion
In conclusion, H2O presents a compelling suite of machine learning tools that cater to a wide range of data science needs, from predictive modeling and deep learning to unsupervised learning tasks. Its compatibility with the JVM offers robust performance and scalability, while the intuitive REST interface and dedicated libraries for Python and R ensure accessibility across different programming environments. Particularly, the seamless integration with Apache Spark via Sparkling Water expands its utility, enabling users to leverage the distributed computing power of Spark alongside H2O's advanced algorithms. This article has introduced H2O's capabilities, demonstrating how easily one can train and evaluate models using Python, highlighting the flexibility and power of H2O.
As you embark on your data science journey with H2O, remember that its strength lies not only in the breadth of its machine learning algorithms but also in its adaptability to different workflows and environments. Whether you prefer the direct control of working within the JVM, the simplicity of Python, the statistical prowess of R, or the distributed computing capabilities of Spark, H2O provides a pathway to sophisticated data analysis and model building. Embrace the fluidity and power of H2O in your data science projects, and explore the depths of its offerings to unlock insightful predictions and transformative analyses.
Addendum: A Special Note for Our Readers
I decided to delay the introduction of subscriptions. You can read the full story here.
If you find our content helpful, there are several ways you can support us:
- The easiest way is to share our articles and links page on social media; it is free and helps us greatly.
- If you want a great experience during the Chinese New Year, I am renting my timeshare in Phuket. A five-night stay in this resort in Phuket costs 11,582 € on Expedia. I am offering it in USD at an over 40% discount compared to that price. I received the Year of the Snake in style.

ReedWeek Timeshare Rental
- If your finances permit it, we are happy over any received donation. It helps us offset the site's running costs and an unexpected tax bill. Any amount is greatly appreciated:
- Finally, some articles have links to relevant goods and services; buying through them will not cost you more. And if you like programming swag, please visit the TuringTacoTales Store on Redbubble. Take a look. Maybe you can find something you like:



